Tóm tắt
Các kỹ thuật RAG (Retrieval-Augmented Generation) đã chứng minh hiệu quả trong việc tích hợp thông tin cập nhật, giảm thiểu ảo giác và nâng cao chất lượng phản hồi, đặc biệt trong các lĩnh vực chuyên môn. Mặc dù nhiều phương pháp RAG đã được đề xuất để cải thiện các mô hình ngôn ngữ lớn thông qua truy hồi phụ thuộc truy vấn, nhưng những phương pháp này vẫn gặp phải hạn chế do tính phức tạp trong triển khai và thời gian phản hồi kéo dài. Thông thường, quy trình làm việc của RAG bao gồm nhiều bước xử lý, mỗi bước có thể được thực hiện theo nhiều cách khác nhau. Trong bài báo này, chúng tôi nghiên cứu các phương pháp RAG hiện có và các tổ hợp tiềm năng của chúng để xác định các thực hành RAG tối ưu. Thông qua các thí nghiệm sâu rộng, chúng tôi đề xuất một số chiến lược triển khai RAG nhằm cân bằng giữa hiệu suất và tính hiệu quả. Hơn nữa, chúng tôi chứng minh rằng các kỹ thuật truy hồi đa phương thức có thể cải thiện đáng kể khả năng trả lời câu hỏi về đầu vào hình ảnh và đẩy nhanh quá trình tạo nội dung đa phương thức bằng cách sử dụng chiến lược “retrieval as generation”. Tài nguyên sẵn sàng tại https://github.com/FudanDNN-NLP/RAG.
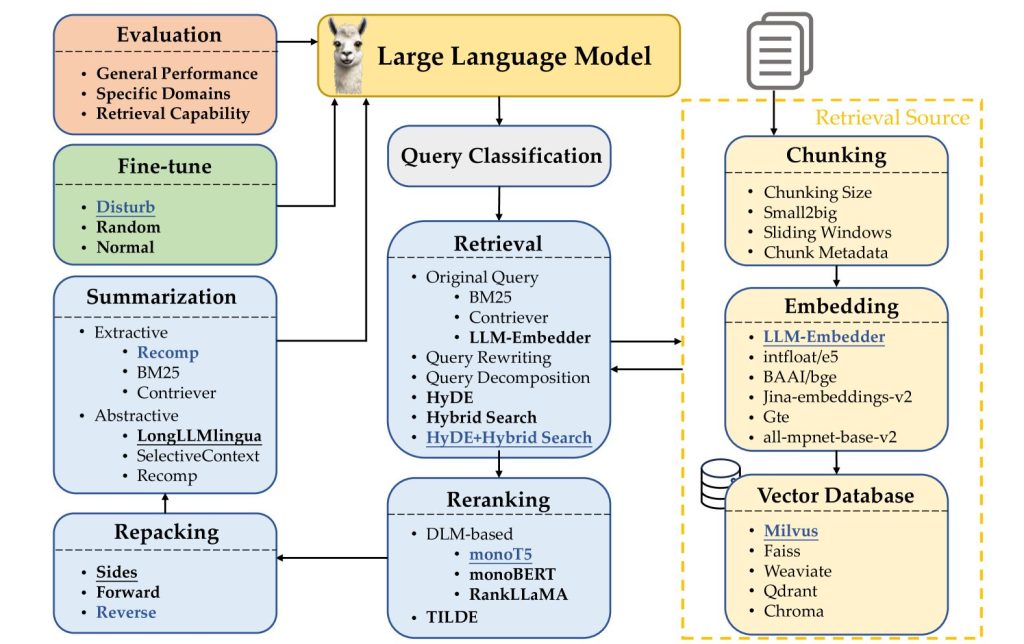
Nghiên cứu này phân tích đóng góp của từng thành phần và cung cấp thông tin chi tiết về các thực hành RAG tối ưu thông qua quá trình thử nghiệm rộng rãi. Các phương thức tùy chọn được xem xét cho mỗi thành phần được đánh dấu in đậm, trong khi các phương pháp được gạch chân cho biết lựa chọn mặc định cho từng mô-đun riêng lẻ. Các phương pháp được đánh dấu màu xanh lam biểu thị lựa chọn hiệu quả nhất được xác định theo kinh nghiệm.
1. Giới thiệu
Các mô hình ngôn ngữ lớn sinh thành (LLM) dễ sản xuất thông tin lỗi thời hoặc bịa đặt sự kiện, mặc dù chúng đã được điều chỉnh phù hợp với sở thích của con người thông qua học tăng cường [1] hoặc các lựa chọn thay thế nhẹ hơn [2, 3, 4, 5]. Kỹ thuật thế hệ gia tăng truy hồi thông tin (RAG) giải quyết những vấn đề này bằng cách kết hợp thế mạnh của các mô hình được huấn luyện trước và dựa trên truy hồi, do đó cung cấp một khung vững chắc để cải thiện hiệu suất mô hình [6]. Hơn nữa, RAG cho phép triển khai nhanh chóng các ứng dụng cho các tổ chức và lĩnh vực cụ thể mà không cần cập nhật các tham số mô hình, miễn là các tài liệu liên quan đến truy vấn được cung cấp.
Nhiều cách tiếp cận RAG đã được đề xuất để cải thiện các mô hình ngôn ngữ lớn (LLM) thông qua truy hồi phụ thuộc truy vấn [7, 8, 6]. Quy trình làm việc RAG điển hình thường chứa nhiều bước xử lý trung gian: phân loại truy vấn (xác định xem cần truy hồi cho một truy vấn đầu vào nhất định hay không), truy hồi (lấy hiệu quả các tài liệu có liên quan đến truy vấn), xếp hạng lại (tinh chỉnh thứ tự của các tài liệu được truy hồi dựa trên mức độ liên quan của chúng với truy vấn), đóng gói lại (sắp xếp các tài liệu được truy hồi thành một tài liệu có cấu trúc để tạo văn bản tốt hơn), tóm tắt (trích xuất thông tin chính để tạo phản hồi từ tài liệu được đóng gói lại và loại bỏ các phần dư thừa) các mô-đun. Việc triển khai RAG cũng yêu cầu các quyết định về cách chia tài liệu thành các phần một cách hợp lý, các loại nhúng được sử dụng để biểu diễn ngữ nghĩa các phần này, lựa chọn cơ sở dữ liệu vector để lưu trữ hiệu quả các biểu diễn tính năng và các phương pháp để tinh chỉnh hiệu quả các LLM (xem Hình 1).
Điều làm cho việc triển khai RAG phức tạp và đầy thách thức là tính biến đổi trong việc thực hiện từng bước xử lý. Ví dụ, trong việc truy hồi các tài liệu có liên quan cho một truy vấn đầu vào, có thể sử dụng nhiều phương pháp khác nhau. Một cách tiếp cận liên quan đến việc viết lại truy vấn trước và sử dụng các truy vấn được viết lại để truy hồi [9]. Ngoài ra, các phản hồi giả cho truy vấn có thể được tạo ra trước tiên và so sánh độ tương đồng giữa các phản hồi giả này với các tài liệu nền để truy hồi [10]. Một lựa chọn khác là trực tiếp sử dụng các mô hình nhúng, thường được huấn luyện theo cách đối sánh sử dụng các cặp truy vấn-phản hồi tích cực và tiêu cực [11, 12]. Các kỹ thuật được chọn cho từng bước và sự kết hợp của chúng ảnh hưởng đáng kể đến cả hiệu quả và tính hiệu quả của các hệ thống RAG. Theo như chúng tôi biết, chưa có nỗ lực hệ thống nào theo đuổi việc triển khai RAG tối ưu, đặc biệt là cho toàn bộ quy trình làm việc RAG.
Trong nghiên cứu này, chúng tôi nhằm mục đích xác định các thực tiễn tốt nhất cho RAG thông qua quá trình thử nghiệm rộng rãi. Do không thể kiểm tra tất cả các tổ hợp có thể có của các phương pháp này, chúng tôi áp dụng phương pháp ba bước để xác định các thực tiễn RAG tối ưu. Đầu tiên, chúng tôi so sánh các phương pháp đại diện cho từng bước RAG (hoặc mô-đun) và chọn ra tối đa ba phương pháp có hiệu suất tốt nhất. Tiếp theo, chúng tôi đánh giá tác động của từng phương pháp đối với hiệu suất tổng thể của RAG bằng cách kiểm tra từng phương pháp một lần cho một bước riêng lẻ, trong khi giữ các mô-đun RAG khác không thay đổi. Điều này cho phép chúng tôi xác định phương pháp hiệu quả nhất cho từng bước dựa trên sự đóng góp và tương tác của nó với các mô-đun khác trong quá trình tạo phản hồi. Sau khi chọn phương pháp tốt nhất cho một mô-đun, nó được sử dụng trong các thí nghiệm tiếp theo. Cuối cùng, chúng tôi khám phá theo kinh nghiệm một vài tổ hợp hứa hẹn phù hợp cho các tình huống ứng dụng khác nhau, nơi hiệu quả có thể được ưu tiên hơn hiệu suất hoặc ngược lại. Dựa trên những phát hiện này, chúng tôi đề xuất một số chiến lược triển khai RAG nhằm cân bằng giữa hiệu suất và tính hiệu quả.
Nghiên cứu này mang lại ba đóng góp chính:
• Thông qua quá trình thử nghiệm rộng rãi, chúng tôi đã điều tra chuyên sâu các cách tiếp cận RAG hiện có và các tổ hợp của chúng để xác định và đề xuất các thực tiễn RAG tối ưu.
• Chúng tôi giới thiệu một framework đánh giá toàn diện bao gồm các số liệu đánh giá và bộ dữ liệu tương ứng để đánh giá toàn diện hiệu suất của các mô hình, tổng quát, chuyên biệt (hoặc theo lĩnh vực) và liên quan đến RAG.
• Chúng tôi chứng minh rằng việc tích hợp các kỹ thuật truy hồi đa phương thức có thể cải thiện đáng kể khả năng trả lời câu hỏi trên các đầu vào hình ảnh và đẩy nhanh quá trình tạo nội dung đa phương thức thông qua chiến lược “retrieval as generation”.
2. Công việc liên quan
Đảm bảo tính chính xác của các phản hồi được tạo bởi các Mô hình Ngôn ngữ Lớn (LLM) như ChatGPT [13] và LLaMA [14] là điều cần thiết. Tuy nhiên, việc đơn giản là tăng kích thước mô hình không giải quyết được vấn đề ảo giác [15, 16] một cách cơ bản, đặc biệt trong các tác vụ đòi hỏi nhiều kiến thức và lĩnh vực chuyên môn. Thế hệ gia tăng truy hồi (RAG) giải quyết những thách thức này bằng cách truy hồi các tài liệu có liên quan từ các cơ sở tri thức bên ngoài, cung cấp ngữ cảnh chính xác, theo thời gian thực và theo lĩnh vực cụ thể cho các LLM [6]. Các công trình trước đây đã tối ưu hóa quy trình RAG thông qua chuyển đổi truy vấn và truy hồi, nâng cao hiệu suất truy hồi và tinh chỉnh cả bộ truy hồi và bộ tạo. Các tối ưu hóa này cải thiện sự tương tác giữa các truy vấn đầu vào, cơ chế truy hồi và quá trình tạo, đảm bảo tính chính xác và liên quan của các phản hồi.
2.1. Chuyển đổi truy vấn (Query) và truy hồi (Retrieval)
Truy hồi hiệu quả đòi hỏi truy vấn phải chính xác, rõ ràng và chi tiết. Ngay cả khi được chuyển đổi thành các nhúng, những khác biệt về ngữ nghĩa giữa các truy vấn và tài liệu liên quan vẫn có thể tồn tại. Các công trình trước đây đã khám phá các phương pháp để nâng cao thông tin truy vấn thông qua chuyển đổi truy vấn, do đó cải thiện hiệu suất truy hồi. Ví dụ, Query2Doc [17] và HyDE [10] tạo các tài liệu giả từ các truy vấn ban đầu để cải thiện truy hồi, trong khi TOC [18] phân tách các truy vấn thành các truy vấn con, tổng hợp nội dung được truy hồi để có kết quả cuối cùng.
Các nghiên cứu khác tập trung vào việc chuyển đổi các tài liệu nguồn truy hồi. LlamaIndex [19] cung cấp giao diện để tạo các truy vấn giả cho các tài liệu truy hồi, cải thiện khả năng khớp với các truy vấn thực. Một số công trình sử dụng học tương phản để đưa các nhúng truy vấn và tài liệu gần nhau hơn trong không gian ngữ nghĩa [20, 12, 21]. Xử lý hậu kỳ các tài liệu được truy hồi là một phương pháp khác để cải thiện đầu ra của bộ tạo, với các kỹ thuật như tóm tắt nhắc nhở phân cấp [22] và sử dụng các bộ nén tóm tắt và trích xuất [23] để giảm độ dài ngữ cảnh và loại bỏ sự dư thừa [24].
2.2. Chiến lược cải thiện bộ truy hồi (Retriever)
Phương pháp phân đoạn và nhúng tài liệu ảnh hưởng đáng kể đến hiệu suất truy hồi. Các chiến lược phân đoạn thông thường chia tài liệu thành các phần nhỏ, nhưng việc xác định độ dài đoạn tối ưu có thể là một thách thức. Các đoạn nhỏ có thể làm phân mảnh các câu, trong khi các đoạn lớn có thể bao gồm ngữ cảnh không liên quan. LlamaIndex [19] tối ưu hóa phương pháp phân đoạn như Small2Big và cửa sổ trượt. Các đoạn được truy hồi có thể không liên quan và số lượng có thể lớn, do đó cần phải xếp hạng lại để lọc các tài liệu không liên quan. Một cách tiếp cận xếp hạng lại phổ biến sử dụng các mô hình ngôn ngữ sâu như BERT [25], T5 [26] hoặc LLaMA [27], đòi hỏi các bước suy luận chậm trong quá trình xếp hạng lại nhưng mang lại hiệu suất tốt hơn. TILDE [28, 29] đạt được hiệu quả bằng cách tính toán trước và lưu trữ xác suất của các thuật ngữ truy vấn, xếp hạng tài liệu dựa trên tổng của chúng.
2.3. Retriever and Generator Fine-tuning
Tinh chỉnh trong khung RAG là rất quan trọng để tối ưu hóa cả bộ truy hồi và bộ tạo. Một số nghiên cứu tập trung vào việc tinh chỉnh bộ tạo để tận dụng tốt hơn ngữ cảnh của bộ truy hồi [30, 31, 32], đảm bảo nội dung được tạo ra trung thực và mạnh mẽ. Các nghiên cứu khác tinh chỉnh bộ truy hồi để học cách truy hồi các đoạn văn có lợi cho bộ tạo [33, 34, 35]. Các cách tiếp cận toàn diện coi RAG như một hệ thống tích hợp, tinh chỉnh cả bộ truy hồi và bộ tạo cùng nhau để nâng cao hiệu suất tổng thể [36, 37, 38], bất chấp những thách thức về độ phức tạp và tích hợp gia tăng.
Nhiều bài nghiên cứu tổng quan đã thảo luận chi tiết về các hệ thống RAG hiện tại, bao gồm các khía cạnh như sinh văn bản [7, 8], tích hợp với LLM [6, 39], đa phương thức [40] và nội dung do AI tạo [41]. Mặc dù các bài nghiên cứu này cung cấp cái nhìn tổng quan toàn diện về các phương pháp RAG hiện có, việc lựa chọn thuật toán phù hợp cho triển khai thực tế vẫn là một thách thức. Trong bài báo này, chúng tôi tập trung vào các thực tiễn tốt nhất để áp dụng các phương pháp RAG, thúc đẩy sự hiểu biết và ứng dụng RAG trong các LLM.

Hình 2: Phân loại yêu cầu truy hồi (retrieval) cho các tác vụ khác nhau. Trong trường hợp không có thông tin được cung cấp, chúng tôi phân biệt các tác vụ dựa trên chức năng của mô hình.
3. RAG Workflow
Mục này sẽ chi tiết về các thành phần của quy trình làm việc RAG. Đối với mỗi mô-đun, chúng tôi xem xét lại các cách tiếp cận thường được sử dụng và chọn phương pháp mặc định và phương pháp thay thế cho quy trình cuối cùng của chúng tôi. Mục 4 sẽ thảo luận về các thực tiễn tốt nhất. Hình 1 trình bày quy trình làm việc và các phương pháp cho từng mô-đun. Thiết lập thí nghiệm chi tiết, bao gồm bộ dữ liệu, các tham số siêu và kết quả được cung cấp trong Phụ lục A.
3.1. Phân loại truy vấn (Query Classification)
Không phải tất cả các truy vấn đều yêu cầu tăng cường truy hồi do các khả năng vốn có của LLM. Mặc dù RAG có thể cải thiện độ chính xác của thông tin và giảm ảo giác, việc truy hồi thường xuyên có thể làm tăng thời gian phản hồi. Do đó, chúng tôi bắt đầu bằng cách phân loại các truy vấn để xác định tính cần thiết của việc truy hồi. Các truy vấn yêu cầu truy hồi sẽ đi qua các mô-đun RAG; các truy vấn khác được LLM xử lý trực tiếp.
Truy hồi thường được khuyến nghị khi cần kiến thức vượt ra ngoài các tham số của mô hình. Tuy nhiên, tính cần thiết của việc truy hồi phụ thuộc vào từng tác vụ. Ví dụ, một LLM được huấn luyện đến năm 2023 có thể xử lý yêu cầu dịch cho “Sora được phát triển bởi OpenAI” mà không cần truy hồi. Ngược lại, yêu cầu giới thiệu về cùng chủ đề sẽ yêu cầu truy hồi để cung cấp thông tin có liên quan.
Do đó, chúng tôi đề xuất phân loại nhiệm vụ theo loại để xác định xem truy vấn có cần truy xuất hay không. Chúng tôi phân loại:
| Model | Metrics | |||
| Acc | Prec | Rec | F1 | |
| BERT-base-multilingual | 0.95 | 0.96 | 0.94 | 0.95 |
15 nhiệm vụ dựa trên việc chúng có cung cấp đủ thông tin hay không, với các tác vụ cụ thể và ví dụ được minh họa trong Hình 2. Đối với các tác vụ hoàn toàn dựa trên thông tin do người dùng cung cấp, chúng tôi ký hiệu là “đủ”, không cần truy hồi; ngược lại, chúng tôi ký hiệu là “không đủ” và có thể cần truy hồi. Chúng tôi huấn luyện một bộ phân loại để tự động hóa quá trình ra quyết định này. Chi tiết về thử nghiệm được trình bày trong Phụ lục A.1. Mục 4 sẽ khám phá tác động của phân loại truy vấn lên quy trình làm việc, so sánh các tình huống có và không có phân loại.
3.2. Phân đoạn (Chunking)
Phân đoạn văn bản thành các đoạn nhỏ hơn là rất quan trọng để nâng cao độ chính xác truy hồi và tránh các vấn đề về độ dài trong LLM. Quá trình này có thể được áp dụng ở các mức độ chi tiết khác nhau, chẳng hạn như cấp độ token (ký hiệu), cấp độ câu và cấp độ ngữ nghĩa.
- Token-level Chunking: Đơn giản nhưng có thể chia tách các câu, ảnh hưởng đến chất lượng truy hồi.
- Semantic-level Chunking: Sử dụng LLM để xác định điểm ngắt đoạn, bảo vệ ngữ cảnh nhưng tốn thời gian.
- Sentence-level Chunking: Cân bằng giữa việc bảo vệ ngữ nghĩa của văn bản với sự đơn giản và hiệu quả.
Trong nghiên cứu này, chúng tôi sử dụng phân đoạn cấp độ câu để cân bằng giữa tính đơn giản và bảo vệ ngữ nghĩa. Chúng tôi kiểm tra phân đoạn theo bốn chiều:
| Embedding Model | namespace-Pt/msmarco | |||||
| MRR@1 | MRR@1 | MRR@10 | MRR@100 | R@1 | R@10 | R@100 |
| BAAI/LLM-Embedder [20] | 24.79 | 37.58 | 38.62 | 24.07 | 66.45 | 90.75 |
| BAAI/bge-base-en-v1.5 [12] | 23.34 | 35.80 | 36.94 | 22.63 | 64.12 | 90.13 |
| BAAI/bge-small-en-v1.5 [12] | 23.27 | 35.78 | 36.89 | 22.65 | 63.92 | 89.80 |
| BAAI/bge-large-en-v1.5 [12] | 24.63 | 37.48 | 38.59 | 23.91 | 65.57 | 90.60 |
| BAAI/bge-large-en [12] | 24.84 | 37.66 | 38.73 | 24.13 | 66.09 | 90.64 |
| BAAI/bge-small-en [12] | 23.28 | 35.79 | 36.91 | 22.62 | 63.96 | 89.67 |
| BAAI/bge-base-en [12] | 23.47 | 35.94 | 37.07 | 22.73 | 64.17 | 90.14 |
| Alibaba-NLP/gte-large-en-v1.5 [21] | 8.93 | 15.60 | 16.71 | 8.67 | 32.28 | 60.36 |
| thenlper/gte-base [21] | 7.42 | 13.23 | 14.30 | 7.21 | 28.27 | 56.20 |
| thenlper/gte-small [21] | 7.97 | 14.81 | 15.95 | 7.71 | 32.07 | 61.08 |
| jinaai/jina-embeddings-v2-small-en [42] | 8.07 | 15.02 | 16.12 | 7.87 | 32.55 | 60.36 |
| intfloat/e5-small-v2 [11] | 10.04 | 18.23 | 19.41 | 9.74 | 38.92 | 68.42 |
| intfloat/e5-large-v2 [11] | 9.58 | 17.94 | 19.03 | 9.35 | 39.00 | 66.11 |
| sentence-transformers/all-mpnet-base-v2 | 5.80 | 11.26 | 12.26 | 5.66 | 25.57 | 50.94 |
3.2.1 Chunk Size
Chunk size (Kích thước đoạn) ảnh hưởng đáng kể đến hiệu suất. Các đoạn lớn hơn cung cấp nhiều ngữ cảnh hơn, cải thiện khả năng hiểu nhưng lại làm tăng thời gian xử lý. Các đoạn nhỏ hơn cải thiện khả năng truy hồi và giảm thời gian nhưng có thể thiếu ngữ cảnh cần thiết.
Việc tìm kiếm kích thước đoạn tối ưu liên quan đến sự cân bằng giữa một số số liệu như độ trung thực và mức độ liên quan. Độ trung thực đo lường liệu phản hồi có bị ảo giác hay khớp với các văn bản được truy hồi.
| Chunk Size | lyft_2021 | |
| AverageFaithfulness | AverageRelevancy | |
| 2048 | 80.37 | 91.11 |
| 1024 | 94.26 | 95.56 |
| 512 | 97.59 | 97.41 |
| 256 | 97.22 | 97.78 |
| 128 | 95.74 | 97.22 |
Mức độ liên quan đo lường mức độ khớp giữa các văn bản được truy hồi và phản hồi với các truy vấn. Chúng tôi sử dụng mô-đun đánh giá của LlamaIndex [43] để tính toán các số liệu ở trên. Đối với nhúng, chúng tôi sử dụng mô hình text-embedding-ada-00211 platform.openai.com/docs/guides/embeddings/embedding-models hỗ trợ độ dài đầu vào lớn. Chúng tôi chọn zephyr-7b-alpha22 huggingface.co/HuggingFaceH4/zephyr-7b-alpha và gpt-3.5-turbo33 https://openai.com làm mô hình sinh và mô hình đánh giá tương ứng. Kích thước chồng chéo của Chunk size là 20 token. Sáu mươi trang đầu tiên của tài liệu lyft_20214 raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/lyft_2021.pdf được sử dụng làm ngữ liệu, sau đó yêu cầu LLM tạo khoảng một trăm bảy mươi truy vấn theo ngữ liệu đã chọn. Tác động của các Chunk size khác nhau được hiển thị trong Bảng 3.
3.2.2. Kỹ thuật Chunking
Các kỹ thuật nâng cao như small-to-big và sliding window cải thiện chất lượng truy hồi bằng cách tổ chức các mối quan hệ giữa các khối chunk. Các khối kích thước nhỏ được sử dụng để khớp với các truy vấn, và các khối lớn hơn bao gồm các khối nhỏ cùng với thông tin ngữ cảnh được trả về.
Để minh họa hiệu quả của các kỹ thuật phân đoạn nâng cao, chúng tôi sử dụng mô hình LLM-Embedder [20] làm mô hình nhúng. Chunk size nhỏ hơn là 175 token, Chunk size lớn hơn là 512 token và chunk overlap là 20 token. Các kỹ thuật như small-to-big và sliding window cải thiện chất lượng truy hồi bằng cách duy trì ngữ cảnh và đảm bảo thông tin liên quan được truy hồi. Kết quả chi tiết được hiển thị trong Bảng 4.
3.2.3. Lựa chọn Embedding Model
Choosing the right embedding model is crucial for effective semantic matching of queries and chunk blocks. We use the evaluation module of FlagEmbedding55https://github.com/FlagOpen/FlagEmbedding which uses the dataset
Chọn mô hình nhúng phù hợp là rất quan trọng để khớp ngữ nghĩa hiệu quả giữa các truy vấn và các đoạn chunk. Chúng tôi sử dụng mô-đun đánh giá của FlagEmbedding github.com/FlagOpen/FlagEmbedding ( sử dụng tập dữ liệu …).
| Chunk Skill | lyft_2021 | |
| AverageFaithfulness | AverageRelevancy | |
| Original | 95.74 | 95.37 |
| small2big | 96.67 | 95.37 |
| sliding window | 97.41 | 96.85 |
sử dụng bộ dữ liệu namespace-Pt/msmarco66 làm truy vấn và namespace-Pt/msmarco-corpus77 làm ngữ liệu để lựa chọn mô hình nhúng mã nguồn mở phù hợp. Như được hiển thị trong Bảng 2, LLM-Embedder [20] đạt được kết quả tương đương với BAAI/bge-large-en [12], tuy nhiên kích thước của mô hình trước nhỏ hơn ba lần so với mô hình sau. Do đó, chúng tôi chọn LLM-Embedder [20] vì sự cân bằng giữa hiệu suất và kích thước.
3.2.4. Thêm Metadata
Việc tăng cường các khối nội dung (chunk block) với metadata như tiêu đề, từ khóa và các câu hỏi giả định có thể cải thiện hiệu suất retrieval, cung cấp nhiều cách hơn để xử lý hậu kỳ các văn bản được tìm nạp và giúp LLMs hiểu tốt hơn thông tin được tìm nạp. Một nghiên cứu chi tiết về việc đưa thêm metadata sẽ được đề cập trong tương lai.
3.3. Vector Databases
Cơ sở dữ liệu vector lưu trữ các vector nhúng cùng với siêu dữ liệu của chúng, cho phép truy xuất hiệu quả các tài liệu có liên quan đến truy vấn thông qua các phương pháp lập chỉ mục khác nhau và phương pháp tìm kiếm xấp xỉ gần nhất (ANN – approximate nearest neighbor).
Để lựa chọn cơ sở dữ liệu vector phù hợp cho nghiên cứu của chúng tôi, chúng tôi đã đánh giá một số lựa chọn dựa trên bốn tiêu chí chính: multiple index types, billion-scale vector support, hybrid search, and cloud-native
| Database | MultipleIndex Type | Billion-Scale | HybridSearch | Cloud-Native |
| Weaviate | ✗ | ✗ | ✓ | ✓ |
| Faiss | ✓ | ✗ | ✗ | ✗ |
| Chroma | ✗ | ✗ | ✓ | ✓ |
| Qdrant | ✗ | ✓ | ✓ | ✓ |
| Milvus | ✓ | ✓ | ✓ | ✓ |
Các khả năng này được lựa chọn dựa trên tác động của chúng đến tính linh hoạt, khả năng mở rộng và dễ dàng triển khai trong cơ sở hạ tầng đám mây hiện đại. Nhiều loại chỉ mục cung cấp sự linh hoạt để tối ưu hóa tìm kiếm dựa trên các đặc điểm dữ liệu và trường hợp sử dụng khác nhau. Hỗ trợ vector tỷ lệ là cần thiết để xử lý các bộ dữ liệu lớn trong các ứng dụng LLM. Tìm kiếm kết hợp kết hợp tìm kiếm vector với tìm kiếm từ khóa truyền thống, nâng cao độ chính xác của việc truy xuất. Cuối cùng, các khả năng đám mây gốc đảm bảo tích hợp liền mạch, khả năng mở rộng và quản lý trong môi trường đám mây. Bảng 5 trình bày so sánh chi tiết của năm cơ sở dữ liệu vector nguồn mở: Weaviate, Faiss, Chroma, Qdrant và Milvus.
Đánh giá của chúng tôi cho thấy Milvus nổi bật là giải pháp toàn diện nhất trong số các cơ sở dữ liệu được đánh giá, đáp ứng tất cả các tiêu chí cần thiết và vượt trội hơn các tùy chọn nguồn mở khác.
| Method | TREC DL19 | TREC DL20 | ||||||||
| mAP | nDCG@10 | R@50 | R@1k | Latency | mAP | nDCG@10 | R@50 | R@1k | Latency | |
| unsupervised | ||||||||||
| BM25 | 30.13 | 50.58 | 38.32 | 75.01 | 0.07 | 28.56 | 47.96 | 46.18 | 78.63 | 0.29 |
| Contriever | 23.99 | 44.54 | 37.54 | 74.59 | 3.06 | 23.98 | 42.13 | 43.81 | 75.39 | 0.98 |
| supervised | ||||||||||
| LLM-Embedder | 44.66 | 70.20 | 49.06 | 84.48 | 2.61 | 45.60 | 68.76 | 61.36 | 84.41 | 0.71 |
| + Query Rewriting | 44.56 | 67.89 | 51.45 | 85.35 | 7.80 | 45.16 | 65.62 | 59.63 | 83.45 | 2.06 |
| + Query Decomposition | 41.93 | 66.10 | 48.66 | 82.62 | 14.98 | 43.30 | 64.95 | 57.74 | 84.18 | 2.01 |
| + HyDE | 50.87 | 75.44 | 54.93 | 88.76 | 7.21 | 50.94 | 73.94 | 63.80 | 88.03 | 2.14 |
| + Hybrid Search | 47.14 | 72.50 | 51.13 | 89.08 | 3.20 | 47.72 | 69.80 | 64.32 | 88.04 | 0.77 |
| + HyDE + Hybrid Search | 52.13 | 73.34 | 55.38 | 90.42 | 11.16 | 53.13 | 72.72 | 66.14 | 90.67 | 2.95 |
3.4. Các phương thức Retrieval
Được cung cấp một truy vấn của người dùng, mô-đun truy xuất sẽ chọn ra các tài liệu có liên quan hàng đầu (top-𝑘) từ một kho tài liệu được xây dựng trước đó dựa trên độ tương đồng giữa truy vấn và các tài liệu. Sau đó, mô hình sinh ra sẽ sử dụng những tài liệu này để xây dựng một câu trả lời phù hợp cho truy vấn. Tuy nhiên, các truy vấn ban đầu thường hoạt động kém hiệu quả do cách diễn đạt kém và thiếu thông tin ngữ nghĩa [6], ảnh hưởng tiêu cực đến quá trình truy xuất. Để giải quyết những vấn đề này, chúng tôi đã đánh giá ba phương pháp chuyển đổi truy vấn bằng cách sử dụng LLM-Embedder được đề xuất trong Phần 3.2 làm bộ mã hóa truy vấn và tài liệu:
• Viết lại truy vấn (Query Rewriting): Viết lại truy vấn giúp tinh chỉnh truy vấn để phù hợp hơn với các tài liệu có liên quan. Lấy cảm hứng từ khung Rewrite-Retrieve-Read [9], chúng tôi yêu cầu một LLM viết lại các truy vấn để cải thiện hiệu suất. • Phân tách truy vấn (Query Decomposition): Cách tiếp cận này liên quan đến việc truy xuất các tài liệu dựa trên các câu hỏi phụ được lấy từ truy vấn ban đầu, vốn phức tạp hơn để hiểu và xử lý. • Sinh tài liệu giả (Pseudo-documents Generation): Cách tiếp cận này tạo ra một tài liệu giả định dựa trên truy vấn của người dùng và sử dụng nhúng của các câu trả lời giả định để truy xuất các tài liệu tương tự. Một ví dụ đáng chú ý là HyDE [10].
Các nghiên cứu gần đây, chẳng hạn như [44], cho thấy việc kết hợp tìm kiếm dựa trên từ vựng với tìm kiếm vector làm tăng đáng kể hiệu suất. Trong nghiên cứu này, chúng tôi sử dụng BM25 để truy xuất thưa thớt và Contriever [45], một bộ mã hóa đối chiếu không giám sát, để truy xuất tràn ngập, đóng vai trò là hai đường cơ sở mạnh mẽ dựa trên Thakur et al. [46].
3.4.1 Kết quả cho các phương pháp truy xuất khác nhau
Chúng tôi đã đánh giá hiệu suất của các phương pháp tìm kiếm khác nhau trên các bộ dữ liệu xếp hạng đoạn văn TREC DL 2019 và 2020. Kết quả được trình bày trong Bảng 6 cho thấy các phương pháp có giám sát vượt trội đáng kể so với các phương pháp không giám sát. Kết hợp với HyDE và tìm kiếm kết hợp, LLM-Embedder đạt điểm cao nhất. Tuy nhiên, việc viết lại truy vấn và phân tách truy vấn không cải thiện hiệu suất truy xuất hiệu quả. Xét về hiệu suất tốt nhất và độ trễ chấp nhận được, chúng tôi đề xuất Tìm kiếm kết hợp với HyDE làm phương pháp truy xuất mặc định. Xem xét đến hiệu quả, Tìm kiếm kết hợp kết hợp truy xuất thưa thớt (BM25) và truy xuất tràn ngập (Nhúng ban đầu) và đạt được hiệu suất đáng kể với độ trễ tương đối thấp.
| Configuration | TREC DL19 | TREC DL20 | ||||||||
| mAP | nDCG@10 | R@50 | R@1k | latency | mAP | nDCG@10 | R@50 | R@1k | Latency | |
| HyDE | ||||||||||
| w/ 1 pseudo-doc | 48.77 | 72.49 | 53.20 | 87.73 | 8.08 | 51.31 | 70.37 | 63.28 | 87.81 | 2.09 |
| w/ 1 pseudo-doc + query | 50.87 | 75.44 | 54.93 | 88.76 | 7.21 | 50.94 | 73.94 | 63.80 | 88.03 | 2.14 |
| w/ 8 pseudo-doc + query | 51.64 | 75.12 | 54.51 | 89.17 | 14.15 | 53.14 | 73.65 | 65.79 | 88.67 | 3.44 |
Table 7: HyDE with different concatenation of hypothetical documents and queries.
| Hyperparameter | TREC DL19 | TREC DL20 | ||||||||
| mAP | nDCG@10 | R@50 | R@1k | latency | mAP | nDCG@10 | R@50 | R@1k | Latency | |
| Hybrid Search | ||||||||||
| 𝛼 = 0.1 | 46.00 | 70.87 | 49.24 | 88.89 | 2.98 | 46.54 | 69.05 | 63.36 | 87.32 | 0.90 |
| 𝛼 = 0.3 | 47.14 | 72.50 | 51.13 | 89.08 | 3.20 | 47.72 | 69.80 | 64.32 | 88.04 | 0.77 |
| 𝛼 = 0.5 | 47.36 | 72.24 | 52.71 | 88.09 | 3.02 | 47.19 | 68.12 | 64.90 | 87.86 | 0.87 |
| 𝛼 = 0.7 | 47.21 | 71.89 | 52.40 | 88.01 | 3.15 | 45.82 | 67.30 | 64.23 | 87.92 | 1.02 |
| 𝛼 = 0.9 | 46.35 | 70.67 | 52.64 | 88.22 | 2.74 | 44.02 | 65.55 | 63.22 | 87.76 | 1.20 |
3.4.2. HyDE với Nối chuỗi Tài liệu và Truy vấn Khác nhau
Bảng 7 hiển thị tác động của các chiến lược nối chuỗi khác nhau cho các tài liệu giả định và truy vấn sử dụng HyDE. Nối chuỗi nhiều tài liệu giả định với truy vấn gốc có thể cải thiện đáng kể hiệu suất truy xuất, mặc dù phải đánh đổi với độ trễ tăng lên, cho thấy sự đánh đổi giữa hiệu quả và hiệu suất truy xuất. Tuy nhiên, việc tăng số lượng tài liệu giả định một cách bừa bãi không mang lại lợi ích đáng kể và làm tăng đáng kể độ trễ, cho thấy việc sử dụng một tài liệu giả định duy nhất là đủ.
3.4.3 Hybrid Search với các trọng số khi Sparse Retrieval
Bảng 8 trình bày tác động của các giá trị 𝛼 khác nhau trong tìm kiếm kết hợp (hybrid search,), trong đó 𝛼 kiểm soát trọng số giữa các thành phần truy xuất thưa thớt và truy xuất dày đặc. Điểm phù hợp (relevance score) được tính như sau:
| 𝑆ℎ=𝛼⋅𝑆𝑠+𝑆𝑑 | (1) |
Trong đó, 𝑆𝑆, 𝑆𝑑 là điểm liên quan được chuẩn hóa lần lượt từ truy vấn thưa thớt và truy vấn đặc, và 𝑆ℎ là điểm truy vấn tổng hợp.
Chúng tôi đã đánh giá năm giá trị 𝛼 khác nhau để xác định ảnh hưởng của chúng lên hiệu suất. Kết quả cho thấy giá trị 𝛼 là 0,3 mang lại hiệu suất tốt nhất, chứng minh rằng việc điều chỉnh 𝛼 phù hợp có thể cải thiện hiệu quả truy vấn đến một mức độ nhất định. Do đó, chúng tôi đã chọn 𝛼 = 0,3 cho các thí nghiệm truy vấn và chính của mình. Các chi tiết triển khai bổ sung được trình bày trong Phụ lục A.2.
| Method | MS MARCO Passage ranking | ||||||
| Base Model | # Params | MRR@1 | MRR@10 | MRR@1k | Hit Rate@10 | Latency | |
| w/o Reranking | |||||||
| Random Ordering | – | – | 0.011 | 0.027 | 0.068 | 0.092 | – |
| BM25 | – | – | 6.52 | 11.65 | 12.59 | 24.63 | – |
| DLM Reranking | |||||||
| monoT5 | T5-base | 220M | 21.62 | 31.78 | 32.40 | 54.07 | 4.5 |
| monoBERT | BERT-large | 340M | 21.65 | 31.69 | 32.35 | 53.38 | 15.8 |
| RankLLaMA | Llama-2-7b | 7B | 22.08 | 32.35 | 32.97 | 54.53 | 82.4 |
| TILDE Reranking | |||||||
| TILDEv2 | BERT-base | 110M | 18.57 | 27.83 | 28.60 | 49.07 | 0.02 |
3.5 Phương thức Reranking
Sau khi truy xuất ban đầu, một giai đoạn sắp xếp lại (reranking) được sử dụng để nâng cao mức độ liên quan của các tài liệu được tìm nạp, đảm bảo thông tin có liên quan nhất xuất hiện ở đầu danh sách. Giai đoạn này sử dụng các phương pháp chính xác hơn và tốn nhiều thời gian hơn để sắp xếp lại các tài liệu hiệu quả, làm tăng độ tương đồng giữa truy vấn và các tài liệu được xếp hạng cao nhất.
Chúng tôi xem xét hai cách tiếp cận trong mô-đun sắp xếp lại của mình: Xếp hạng lại DLM, sử dụng phân loại và Xếp hạng lại TILDE, tập trung vào khả năng truy vấn. Các cách tiếp cận này lần lượt ưu tiên hiệu suất và hiệu quả.
• DLM Reranking: Phương pháp này tận dụng các mô hình ngôn ngữ sâu (DLM) [25, 26, 27] để xếp hạng lại. Các mô hình này được tinh chỉnh để phân loại mức độ liên quan của tài liệu với một truy vấn thành “đúng” hoặc “sai”. Trong quá trình tinh chỉnh, mô hình được huấn luyện với các đầu vào được nối chuỗi của truy vấn và tài liệu, được dán nhãn theo mức độ liên quan. Khi suy luận, các tài liệu được xếp hạng dựa trên xác suất của mã “đúng”.
• TILDE Reranking: TILDE [28, 29] tính toán độc lập khả năng xuất hiện của từng thuật ngữ truy vấn bằng cách dự đoán xác suất của các mã thông báo trên toàn bộ vốn từ của mô hình. Tài liệu được chấm điểm bằng cách cộng tổng các logarit xác suất được tính toán trước của các mã thông báo truy vấn, cho phép xếp hạng lại nhanh chóng khi suy luận. TILDEv2 cải thiện điều này bằng cách chỉ lập chỉ mục các mã thông báo có trong tài liệu, sử dụng mất mát NCE và mở rộng tài liệu, do đó nâng cao hiệu quả và giảm kích thước chỉ mục.
Các thí nghiệm của chúng tôi được tiến hành trên bộ dữ liệu xếp hạng đoạn văn MS MARCO [47], một bộ dữ liệu quy mô lớn dành cho việc hiểu đọc bằng máy. Chúng tôi tuân theo và sửa đổi phần triển khai được cung cấp bởi PyGaggle [26] và TILDE [28], sử dụng các mô hình monoT5, monoBERT, RankLLaMA và TILDEv2. Kết quả xếp hạng lại được hiển thị trong Bảng 9. Chúng tôi đề xuất monoT5 là một phương pháp toàn diện cân bằng giữa hiệu suất và hiệu quả. RankLLaMA phù hợp để đạt được hiệu suất tốt nhất, trong khi TILDEv2 lý tưởng cho trải nghiệm nhanh nhất trên một bộ sưu tập cố định. Chi tiết về thiết lập và kết quả thử nghiệm được trình bày trong Phụ lục A.3.
3.6 Đóng gói tài liệu (Document Repacking)
Thứ tự các tài liệu được cung cấp có thể ảnh hưởng đến hiệu suất của các quá trình tiếp theo, chẳng hạn như tạo câu trả lời bằng LLM. Để giải quyết vấn đề này, chúng tôi tích hợp một mô-đun đóng gói gọn nhẹ vào quy trình làm việc sau khi sắp xếp lại, gồm ba phương thức đóng gói: “forward”, “reverse” và “sides”. Phương pháp “forward” đóng gói lại các tài liệu theo điểm liên quan giảm dần từ giai đoạn sắp xếp lại, trong khi phương pháp “reverse” sắp xếp chúng theo thứ tự tăng dần. Lấy cảm hứng từ Liu et al. [48], người kết luận rằng hiệu suất tối ưu đạt được khi thông tin có liên quan được đặt ở đầu hoặc cuối đầu vào, chúng tôi cũng bao gồm tùy chọn “sides”.
Do phương pháp đóng gói chủ yếu ảnh hưởng đến các mô-đun tiếp theo, nên chúng tôi sẽ chọn phương pháp đóng gói tốt nhất trong Phần 4 bằng cách thử nghiệm nó kết hợp với các mô-đun khác. Trong phần này, chúng tôi chọn phương pháp “sides” làm phương pháp đóng gói mặc định.
| Method | NQ | TQA | HotPotQA | Avg. | Avg. Token | |||
| F1 | #token | F1 | #token | F1 | #token | |||
| w/o Summarization | ||||||||
| Origin Prompt | 27.07 | 124 | 33.61 | 152 | 33.92 | 141 | 31.53 | 139 |
| Extractive Method | ||||||||
| BM25 | 27.97 | 40 | 32.44 | 59 | 28.00 | 63 | 29.47 | 54 |
| Contriever | 23.62 | 42 | 33.79 | 65 | 23.64 | 60 | 27.02 | 56 |
| Recomp (extractive) | 27.84 | 34 | 35.32 | 60 | 29.46 | 58 | 30.87 | 51 |
| Abstractive Method | ||||||||
| SelectiveContext | 25.05 | 65 | 34.25 | 70 | 34.43 | 66 | 31.24 | 67 |
| LongLLMlingua | 21.32 | 51 | 32.81 | 56 | 30.79 | 57 | 28.29 | 55 |
| Recomp (abstractive) | 33.68 | 59 | 35.87 | 61 | 29.01 | 57 | 32.85 | 59 |
3.7 Tóm lại
Kết quả truy xuất có thể chứa thông tin trùng lặp hoặc không cần thiết, có khả năng cản trở LLM tạo ra các phản hồi chính xác. Ngoài ra, các nhắc nhở dài có thể làm chậm quá trình suy luận. Do đó, các phương pháp hiệu quả để tóm tắt các tài liệu được truy xuất là rất quan trọng trong quy trình RAG.
Công việc tóm tắt có thể là dạng trích chọn (extractive) hoặc tóm tắt trừu tượng (abstractive). Phương pháp trích chọn phân đoạn văn bản thành các câu, sau đó chấm điểm và xếp hạng chúng dựa trên mức độ quan trọng. Phương pháp tóm tắt trừu tượng tổng hợp thông tin từ nhiều tài liệu để diễn đạt lại và tạo ra một bản tóm tắt mạch lạc. Các tác vụ này có thể dựa trên truy vấn hoặc không dựa trên truy vấn. Trong bài báo này, vì RAG truy xuất thông tin có liên quan đến truy vấn, chúng tôi chỉ tập trung vào các phương pháp dựa trên truy vấn.
• Recomp: Recomp [23] có các bộ nén trích chọn và trừu tượng. Bộ nén trích chọn chọn các câu hữu ích, trong khi bộ nén trừu tượng tổng hợp thông tin từ nhiều tài liệu.
• LongLLMLingua: LongLLMLingua [49] cải thiện LLMLingua bằng cách tập trung vào thông tin chính liên quan đến truy vấn.
• Selective Context: Selective Context nâng cao hiệu suất của LLM bằng cách xác định và loại bỏ thông tin trùng lặp trong ngữ cảnh đầu vào. Phương pháp này đánh giá mức độ thông tin của các đơn vị từ vựng bằng cách sử dụng thông tin tự tính toán bởi một mô hình ngôn ngữ cơ sở theo nguyên nhân. Phương pháp này không dựa trên truy vấn, cho phép so sánh giữa các cách tiếp cận dựa trên truy vấn và không dựa trên truy vấn.
Chúng tôi đánh giá các phương pháp này trên ba bộ dữ liệu đánh giá: NQ, TriviaQA và HotpotQA. Kết quả so sánh của các phương pháp tóm tắt khác nhau được hiển thị trong Bảng 10. Chúng tôi đề xuất Recomp vì hiệu suất vượt trội của nó. LongLLMLingua không hoạt động tốt nhưng cho thấy khả năng tổng quát hóa tốt hơn vì nó không được đào tạo trên các bộ dữ liệu thử nghiệm này. Do đó, chúng tôi coi nó là một phương pháp thay thế. Các chi tiết triển khai bổ sung và thảo luận về các phương pháp không dựa trên truy vấn được cung cấp trong Phụ lục A.4.
3.8 Generator Fine-tuning
Trong phần này, chúng tôi tập trung vào việc tinh chỉnh bộ tạo câu trả lời (generator) trong khi việc tinh chỉnh bộ truy xuất sẽ được đề cập đến trong các nghiên cứu tương lai. Mục tiêu của chúng tôi là nghiên cứu tác động của việc tinh chỉnh, đặc biệt là ảnh hưởng của bối cảnh có liên quan hoặc không liên quan đến hiệu suất của bộ tạo câu trả lời.
Ký hiệu chính thức, chúng tôi gọi truy vấn đưa vào hệ thống RAG là 𝑥 và 𝒟 là các ngữ cảnh cho đầu vào này. Hàm mất mát khi tinh chỉnh bộ tạo câu trả lời là giá trị log-likelihood âm của kết quả đầu ra thực tế 𝑦.
Để khám phá tác động của việc tinh chỉnh, đặc biệt là các ngữ cảnh có liên quan và không liên quan, chúng tôi định nghĩa 𝑑𝑔𝑜𝑙𝑑 là ngữ cảnh có liên quan đến truy vấn và 𝑑𝑟𝑎𝑛𝑑𝑜𝑚 là ngữ cảnh được truy xuất ngẫu nhiên. Chúng tôi huấn luyện mô hình bằng cách thay đổi thành phần của 𝒟 như sau:
• 𝐷𝑔: Ngữ cảnh được tăng cường bao gồm các tài liệu có liên quan đến truy vấn, được ký hiệu là 𝐷𝑔={𝑑𝑔𝑜𝑙𝑑}.
• 𝐷𝑟: Ngữ cảnh chứa một tài liệu được lấy mẫu ngẫu nhiên, được ký hiệu là 𝐷𝑟={𝑑𝑟𝑎𝑛𝑑𝑜𝑚}.
• 𝐷𝑔𝑟: Ngữ cảnh được tăng cường bao gồm một tài liệu có liên quan và một tài liệu được chọn ngẫu nhiên, được ký hiệu là 𝐷𝑔𝑟={𝑑𝑔𝑜ល𝑑,𝑑𝑟𝑎𝑛𝑑𝑜𝑚}.
• 𝐷𝑔𝑔: Ngữ cảnh được tăng cường bao gồm hai bản sao của một tài liệu có liên quan đến truy vấn, được ký hiệu là 𝐷𝑔𝑔={𝑑𝑔𝑜ល𝑑,𝑑𝑔𝑜ល𝑑}.
Chúng tôi ký hiệu mô hình tạo câu trả lời cơ bản chưa được tinh chỉnh là 𝑀𝑏 , và mô hình được tinh chỉnh theo 𝒟 tương ứng là 𝑀𝑔, 𝑀𝑟, 𝑀𝑔𝑟, 𝑀𝑔𝑔. Chúng tôi đã tinh chỉnh mô hình của mình trên một số bộ dữ liệu về Hỏi-Đáp (QA) và Đọc hiểu

Xác nhận bao phủ (ground-truth coverage) được sử dụng làm tiêu chuẩn đánh giá của chúng tôi vì câu trả lời của tác vụ Hỏi-Đáp thường tương đối ngắn. Chúng tôi chọn Llama-2-7B [50] làm mô hình cơ bản. Tương tự như khi huấn luyện, chúng tôi đánh giá tất cả các mô hình đã được huấn luyện trên các tập hợp xác thực với 𝐷𝑔, 𝐷𝑟, 𝐷𝑔𝑟 và 𝐷∅, trong đó 𝐷∅ chỉ ra suy luận mà không cần truy xuất. Hình 3 trình bày các kết quả chính của chúng tôi.
Các mô hình được huấn luyện với sự kết hợp của tài liệu có liên quan và ngẫu nhiên (𝑀𝑔𝑟) hoạt động tốt nhất khi được cung cấp ngữ cảnh vàng (gold context – ngữ cảnh hoàn hảo) hoặc ngữ cảnh hỗn hợp. Điều này cho thấy việc kết hợp các ngữ cảnh có liên quan và ngẫu nhiên trong quá trình huấn luyện có thể nâng cao khả năng chống chịu của bộ tạo câu trả lời đối với thông tin không liên quan đồng thời đảm bảo sử dụng hiệu quả các ngữ cảnh có liên quan. Do đó, chúng tôi xác định việc tăng cường với một vài tài liệu có liên quan và được chọn ngẫu nhiên trong quá trình huấn luyện là cách tiếp cận tốt nhất. Thông tin chi tiết về bộ dữ liệu, các tham số siêu và kết quả thử nghiệm có thể được tìm thấy trong Phụ lục A.5.
4. Đi tìm kỹ năng triển khai RAG tốt nhất
Trong phần tiếp theo, chúng ta sẽ nghiên cứu các thực tiễn tối ưu để triển khai RAG. Bắt đầu, chúng tôi sử dụng thực tiễn mặc định được xác định trong Phần 3 cho từng mô-đun. Theo quy trình được mô tả trong Hình 1, chúng tôi tuần tự tối ưu các mô-đun riêng lẻ và chọn tùy chọn hiệu quả nhất trong số các lựa chọn thay thế. Quá trình lặp lại này tiếp tục cho đến khi chúng tôi xác định được phương pháp tốt nhất để triển khai mô-đun tóm tắt cuối cùng. Dựa trên Phần 3.8, chúng tôi sử dụng mô hình Llama2-7B-Chat được tinh chỉnh chi tiết, trong đó mỗi truy vấn được tăng cường bởi một vài tài liệu được chọn ngẫu nhiên và có liên quan làm bộ sinh văn bản. Chúng tôi sử dụng Milvus để xây dựng cơ sở dữ liệu vector bao gồm 10 triệu văn bản Wikipedia tiếng Anh và 4 triệu văn bản dữ liệu y tế. Chúng tôi cũng nghiên cứu tác động của việc loại bỏ các mô-đun Phân loại truy vấn, Xếp hạng lại và Tóm tắt để đánh giá đóng góp của chúng.
4.1 Đánh giá toàn diện
Hơn nữa, chúng tôi đã đánh giá các khả năng của RAG trên các tập con được trích xuất từ các bộ dữ liệu này, sử dụng các số liệu được đề xuất trong RAGAs [51], bao gồm Độ trung thực (Faithfulness), Mức độ liên quan ngữ cảnh (Context Relevancy), Mức độ liên quan câu trả lời (Answer Relevancy) và Tính chính xác câu trả lời (Answer Correctness). Ngoài ra, chúng tôi đo Độ tương đồng truy vấn (Retrieval Similarity) bằng cách tính toán độ tương đồng cosin giữa các tài liệu được truy xuất và các tài liệu tham chiếu.
Chúng tôi đã tiến hành các thí nghiệm rộng rãi trên nhiều tác vụ và bộ dữ liệu NLP khác nhau để đánh giá hiệu suất của các hệ thống RAG. Cụ thể: (I) Commonsense Reasoning; (II) Fact Checking; (III) Open-Domain QA; (IV) MultiHop QA; (V) Medical QA. Để biết thêm chi tiết về các tác vụ và bộ dữ liệu tương ứng của chúng, vui lòng tham khảo Phụ lục A.6.
Chúng tôi sử dụng độ chính xác làm số liệu đánh giá cho các tác vụ Lý luận thường thức, Kiểm tra tény và Hỏi-Đáp Y tế. Đối với Hỏi-Đáp Miền mở và Hỏi-Đáp Nhiều bước, chúng tôi sử dụng điểm F1 ở cấp độ token và điểm Exact Match (EM). Điểm RAG cuối cùng được tính toán bằng cách lấy trung bình của năm khả năng RAG được đề cập ở trên. Chúng tôi tuân theo Trivedi et al. [52] và lấy mẫu phụ tối đa 500 ví dụ từ mỗi bộ dữ liệu.
4.2 Kết quả và Phân tích
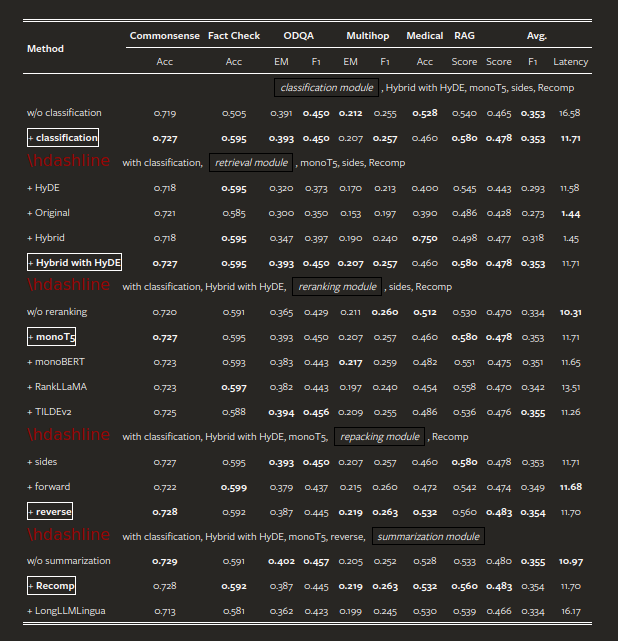
Dựa trên các kết quả thí nghiệm được trình bày trong Bảng 4.1, chúng ta có thể rút ra những hiểu biết chính sau:
- Query Classification Module: Mô-đun này đóng vai trò quan trọng và ảnh hưởng đến cả hiệu quả và tính năng, giúp cải thiện điểm tổng thể trung bình từ 0,428 lên 0,443 và giảm thời gian trễ từ 16,41 xuống còn 11,58 giây cho mỗi truy vấn.
- Retrieval Module: Trong khi phương pháp “Hybrid với HyDE” đạt điểm RAG cao nhất là 0,58, nhưng nó lại tốn rất nhiều tài nguyên tính toán với trung bình 11,71 giây cho mỗi truy vấn. Do đó, các phương pháp “Hybrid” hoặc “Original” được khuyến nghị vì chúng giảm độ trễ toutantoàn duy trì hiệu suất tương đương.
- Reranking Module: Việc thiếu mô-đun sắp xếp lại thứ hạng dẫn đến giảm hiệu suất đáng kể, cho thấy tính cần thiết của nó. MonoT5 đạt điểm trung bình cao nhất, khẳng định hiệu quả của nó trong việc tăng tính liên quan của các tài liệu được truy xuất. Điều này cho thấy vai trò quan trọng của việc sắp xếp lại thứ hạng trong việc nâng cao chất lượng của các phản hồi được tạo.
- Repacking Module: Cấu hình Reverse cho thấy hiệu suất vượt trội, đạt điểm RAG là 0,560. Điều này cho thấy việc đặt ngữ cảnh có liên quan hơn gần với truy vấn sẽ dẫn đến kết quả tốt nhất.
- Summarization Module: Recomp cho thấy hiệu suất vượt trội, mặc dù vẫn có thể đạt được kết quả tương đương với độ trễ thấp hơn bằng cách loại bỏ mô-đun tóm tắt. Tuy nhiên, Recomp vẫn là lựa chọn ưu tiên do khả năng xử lý các hạn chế về độ dài tối đa của trình tạo câu trả lời. Trong các ứng dụng yêu cầu thời gian thực, việc loại bỏ tóm tắt có thể hiệu quả làm giảm thời gian phản hồi. Kết quả thí nghiệm cho thấy mỗi mô-đun đều đóng góp riêng biệt vào hiệu suất tổng thể của hệ thống RAG. Mô-đun phân loại truy vấn cải thiện độ chính xác và giảm độ trễ, trong khi các mô-đun truy vấn và sắp xếp lại thứ hạng cải thiện đáng kể khả năng xử lý các truy vấn đa dạng của hệ thống. Các mô-đun đóng gói lại và tóm tắt tinh chỉnh thêm đầu ra của hệ thống, đảm bảo phản hồi chất lượng cao trên các tác vụ khác nhau.
5 Thảo luận
5.1 Kỹ thuật tốt nhất để triển khai RAG
Dựa trên các kết quả thí nghiệm, chúng tôi đề xuất hai công thức hoặc phương pháp thực hiện hệ thống RAG riêng biệt, mỗi phương pháp được tùy chỉnh để giải quyết các yêu cầu cụ thể: một phương pháp tập trung vào việc tối đa hóa hiệu suất và phương pháp khác nhằm mục tiêu cân bằng giữa hiệu quả và tính năng.
Thực hành Hiệu suất Tốt nhất: Để đạt được hiệu suất cao nhất, chúng tôi đề nghị sử dụng mô-đun phân loại truy vấn, phương pháp “Hybrid với HyDE” cho truy vấn, sử dụng monoT5 để sắp xếp lại thứ hạng, chọn Reverse để đóng gói lại và tận dụng Recomp để tóm tắt. Cấu hình này cho điểm trung bình cao nhất là 0,483, mặc dù quá trình tính toán rất tốn nhiều tài nguyên.
Thực hành Cân bằng Giữa Hiệu quả và Tính năng: Để đạt được sự cân bằng giữa hiệu suất và hiệu quả, chúng tôi đề nghị sử dụng mô-đun phân loại truy vấn, triển khai phương pháp Hybrid để truy vấn, sử dụng TILDEv2 để sắp xếp lại thứ hạng, chọn Reverse để đóng gói lại và sử dụng Recomp để tóm tắt. Do mô-đun truy vấn chiếm phần lớn thời gian xử lý trong hệ thống, việc chuyển sang phương pháp Hybrid trong khi giữ nguyên các mô-đun khác có thể giảm đáng kể độ trễ toutantoàn duy trì hiệu suất tương đương.

Phần trên minh họa quá trình truy hồi ảnh từ văn bản. Bắt đầu, truy vấn dạng văn bản được sử dụng để tìm các hình ảnh có độ tương đồng cao nhất trong cơ sở dữ liệu. Nếu tìm thấy độ tương đồng cao, ảnh sẽ được trả về trực tiếp. Ngược lại, một mô hình tạo ảnh sẽ được sử dụng để tạo và trả về một hình ảnh phù hợp.
Phần dưới minh họa quá trình truy hồi văn bản từ ảnh. Trong trường hợp này, hình ảnh do người dùng cung cấp sẽ được so sánh với các hình ảnh trong cơ sở dữ liệu để tìm ra hình ảnh có độ tương đồng cao nhất. Nếu tìm thấy độ tương đồng cao, chú thích được lưu trữ trước đó của hình ảnh khớp sẽ được trả về. Ngược lại, một mô hình chú thích ảnh sẽ tạo và trả về một chú thích mới.
5.2 Multimodal Extension
Chúng tôi đã mở rộng RAG cho các ứng dụng đa phương thức. Cụ thể, chúng tôi đã tích hợp khả năng tìm kiếm text2image (văn bản đến ảnh) và image2text (ảnh đến văn bản) vào hệ thống với một bộ sưu tập khổng lồ các mô tả văn bản và hình ảnh được ghép nối làm nguồn tìm kiếm. Như được mô tả trong Hình 4, khả năng text2image giúp tăng tốc quá trình tạo ảnh khi truy vấn của người dùng khớp với mô tả văn bản của hình ảnh được lưu trữ (tức là chiến lược “tìm kiếm như tạo”). Trong khi đó, chức năng image2text phát huy tác dụng khi người dùng cung cấp hình ảnh và tham gia hội thoại về hình ảnh đầu vào. Các khả năng RAG đa phương thức này mang lại những lợi thế sau:
- Tính xác thực (Groundedness): Các phương pháp tìm kiếm cung cấp thông tin từ các tài liệu đa phương thức được xác minh, do đó đảm bảo tính xác thực và tính đặc thù. Ngược lại, việc tạo theo thời gian thực dựa vào các mô hình để tạo nội dung mới, đôi khi có thể dẫn đến lỗi thực tế hoặc không chính xác.
- Hiệu quả (Efficiency): Các phương pháp tìm kiếm thường hiệu quả hơn, đặc biệt là khi câu trả lời đã tồn tại trong các tài liệu được lưu trữ. Ngược lại, các phương pháp tạo có thể yêu cầu nhiều tài nguyên tính toán hơn để tạo nội dung mới, đặc biệt đối với hình ảnh hoặc văn bản dài.
- Tính bảo trì (Maintainability): Các mô hình tạo thường đòi hỏi phải điều chỉnh chi tiết cẩn thận để phù hợp với các ứng dụng mới. Ngược lại, các phương pháp dựa trên tìm kiếm có thể được cải thiện để đáp ứng các yêu cầu mới đơn giản bằng cách tăng kích thước và nâng cao chất lượng của các nguồn tìm kiếm.
Chúng tôi có kế hoạch mở rộng việc áp dụng chiến lược này để bao gồm các phương thức khác, chẳng hạn như video và giọng nói, đồng thời khám phá các kỹ thuật tìm kiếm đa phương thức hiệu quả và tiết kiệm.
6 Kết luận
Trong nghiên cứu này, chúng tôi đặt mục tiêu xác định các thực tiễn tối ưu để triển khai thế hệ gia tăng truy hồi (RAG) nhằm cải thiện chất lượng và độ tin cậy của nội dung do các mô hình ngôn ngữ lớn tạo ra. Chúng tôi đã tiến hành đánh giá hệ thống một loạt các giải pháp tiềm năng cho từng mô-đun trong khuôn khổ RAG và đề xuất cách tiếp cận hiệu quả nhất cho mỗi mô-đun. Hơn nữa, chúng tôi đã giới thiệu một chuẩn đánh giá toàn diện cho các hệ thống RAG và tiến hành các thí nghiệm rộng rãi để xác định các thực tiễn tốt nhất trong số các lựa chọn thay thế khác nhau. Những phát hiện của chúng tôi không chỉ góp phần vào việc hiểu sâu hơn về các hệ thống thế hệ gia tăng truy hồi mà còn thiết lập nền tảng cho các nghiên cứu trong tương lai.
Các giới hạn
Chúng tôi đã đánh giá tác động của các phương pháp khác nhau để tinh chỉnh các mô hình sinh văn bản LLM. Các nghiên cứu trước đây đã chứng minh tính khả thi của việc huấn luyện đồng thời cả mô hình truy hồi và mô hình sinh văn. Chúng tôi mong muốn khám phá khả năng này trong tương lai. Trong nghiên cứu này, chúng tôi đã áp dụng nguyên tắc thiết kế mô-đun để đơn giản hóa việc tìm kiếm các triển khai RAG tối ưu, do đó giảm thiểu độ phức tạp. Do chi phí khổng lồ liên quan đến việc xây dựng cơ sở dữ liệu vector và tiến hành thí nghiệm, việc đánh giá của chúng tôi bị giới hạn trong việc nghiên cứu hiệu quả và ảnh hưởng của các kỹ thuật phân đoạn tiêu biểu trong mô-đun phân đoạn. Sẽ rất thú vị để khám phá thêm tác động của các kỹ thuật phân đoạn khác nhau lên toàn bộ hệ thống RAG. Mặc dù chúng tôi đã thảo luận về việc ứng dụng RAG trong lĩnh vực Xử lý Ngôn ngữ Tự nhiên (NLP) và mở rộng phạm vi của nó sang tạo ảnh, một hướng đi hấp dẫn cho nghiên cứu trong tương lai sẽ liên quan đến việc mở rộng nghiên cứu này sang các phương thức khác như giọng nói và video.
Cảm ơn
Các tác giả xin chân thành cảm ơn các bình luận viên ẩn danh vì những góp ý quý báu của họ. Công trình này được hỗ trợ bởi Quỹ Khoa học Tự nhiên Quốc gia Trung Quốc (Mã số: 62076068).




0 Lời bình